Dense future frames preserve visual detail, but require costly iterative generation and include pixel-level variation that is not necessary for choosing the next action chunk.
Robot learning project
LaWAM: Latent World Action Models for Efficient Dynamics-Aware Robot Policies
LaWAM exposes predictive dynamics to VLA policies through compact latent visual subgoals instead of reconstructed future video, enabling dynamics-aware robot control with low-latency inference.
98.6%
LIBERO average SR
91.22%
RoboTwin SR
187 ms
per action chunk
Up to 24x
speedup vs pixel WAMs
Why Latent Futures
Video imagination slows robot control.
World-Action Models help policies reason about how scenes evolve under action, but future-image or future-video prediction spends latency and model capacity on pixel-level synthesis. LaWAM keeps the future-conditioned control principle while moving prediction into the latent space of pretrained visual encoders such as DINOv3, where one horizon subgoal captures the scene change needed for the next action chunk.
A policy-predicted latent action drives LaWM to produce one spatially structured future observation feature that directly conditions the downstream action generator.
Method
Learn LaWM, then drive it with the policy.
LaWAM trains a latent action model in a frozen visual feature space, retains its forward decoder as LaWM, and uses latent-action distillation so the policy can predict the transition code that produces the needed future subgoal. The dynamics prior is learned from roughly 3,000 hours of robot videos and 1,500 hours of egocentric human videos, while policy integration uses robot trajectories with language instructions.
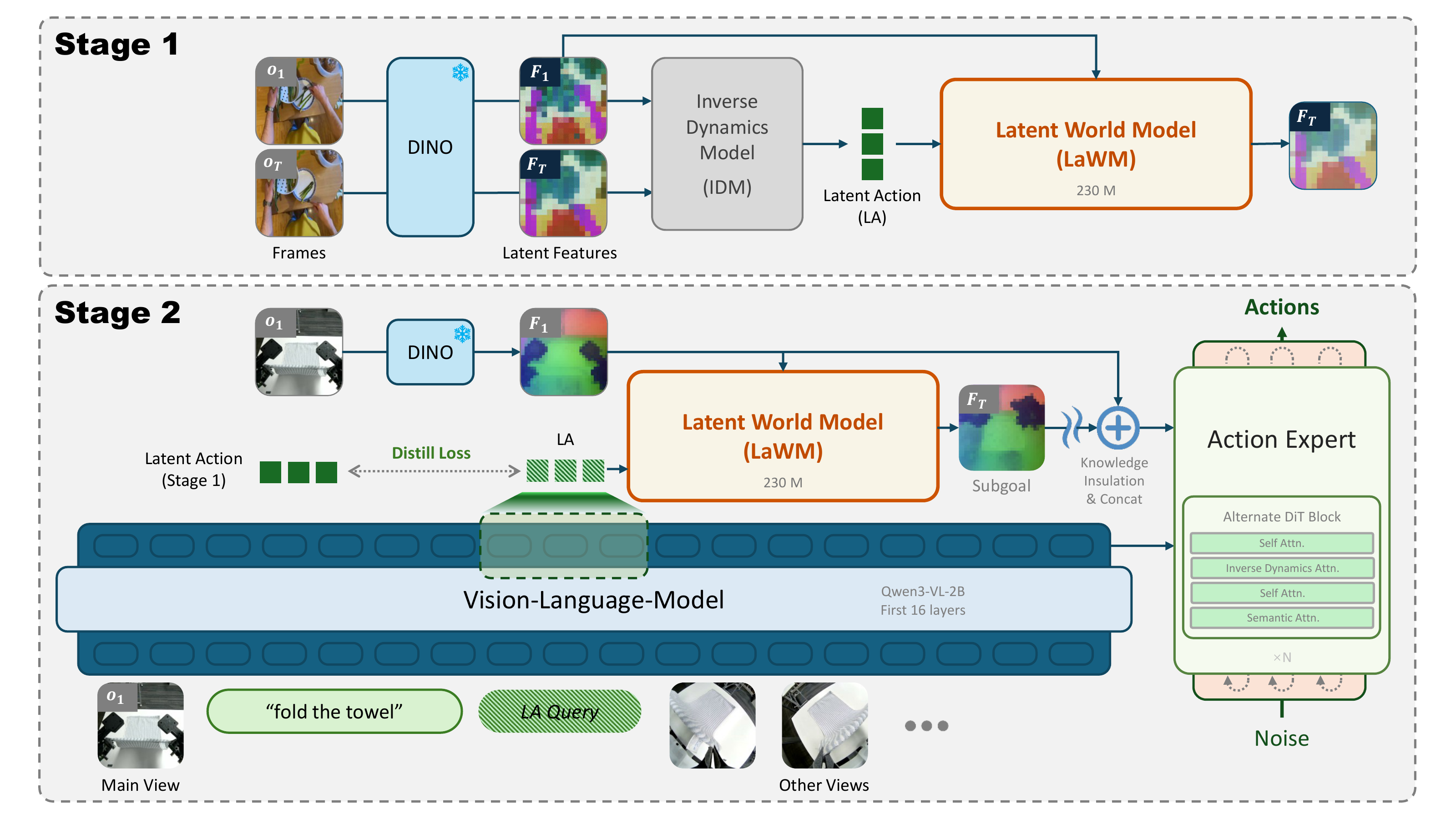
Learn LaWM
Encode current and horizon observations with a frozen visual encoder such as DINOv3, infer continuous latent actions, and train the forward decoder to predict the horizon feature.
Distill subgoals
Use latent-action distillation to teach the policy prior to predict transition codes from the current observation and language instruction.
Generate actions
At test time, one non-iterative LaWM pass produces a latent visual subgoal that conditions the Alternate-DiT action expert for chunk-level control.
Three-Minute Overview
Watch the LaWAM project video.
The video summarizes the latent-subgoal interface, benchmark results, and qualitative robot rollouts shown below.
Results
High success with low-latency latent prediction.
Across LIBERO, RoboTwin, and physical manipulation tasks, LaWAM achieves state-of-the-art or competitive success while replacing pixel-space rollouts with a compact 230M-parameter LaWM.
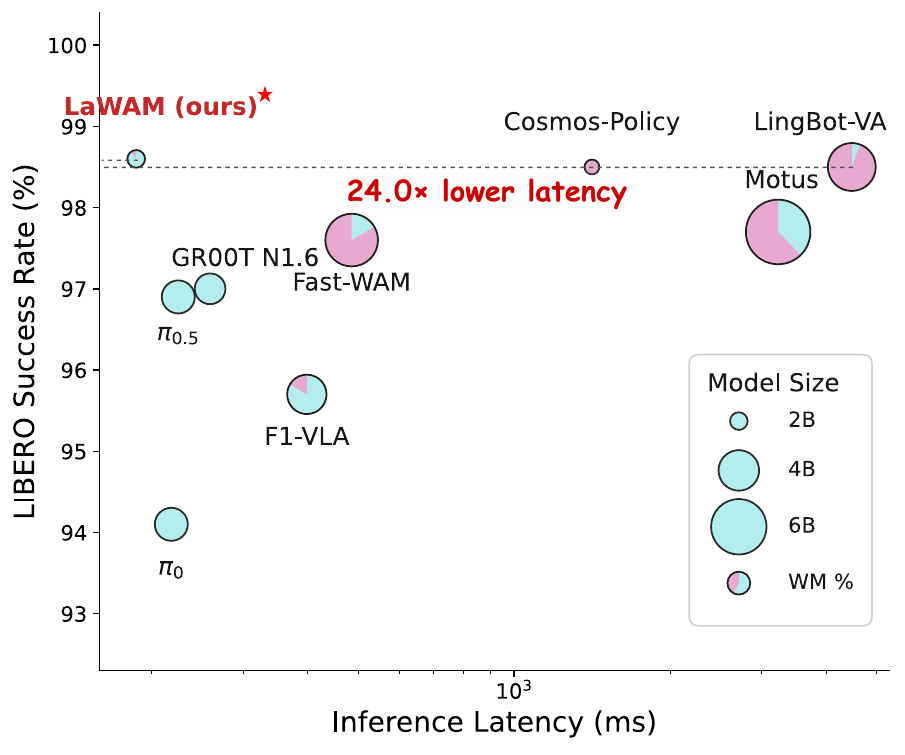
| Method | Model | Latency | Avg. SR |
|---|---|---|---|
| pi0.5 | 3.5B | 220 ms | 96.9 |
| Cosmos-Policy | 2.1B | 1413 ms | 98.5 |
| LingBot-VA | 5.5B | 4482 ms | 98.5 |
| LaWAM | 2.3B | 187 ms | 98.6 |
RoboTwin
Coordinated bimanual manipulation across 50 RoboTwin tasks, with 100 trials per task under clean and randomized scenes.
Real-World Transfer
Best average real-world success across rigid-object, articulated-object, and deformable-object tasks, ranking first on pick-and-place, drawer opening, and towel folding. The real-world protocol uses a Franka arm for the first two tasks, a Quanta X1 bimanual robot for towel folding, and 30 trials per task.
LIBERO object tasks
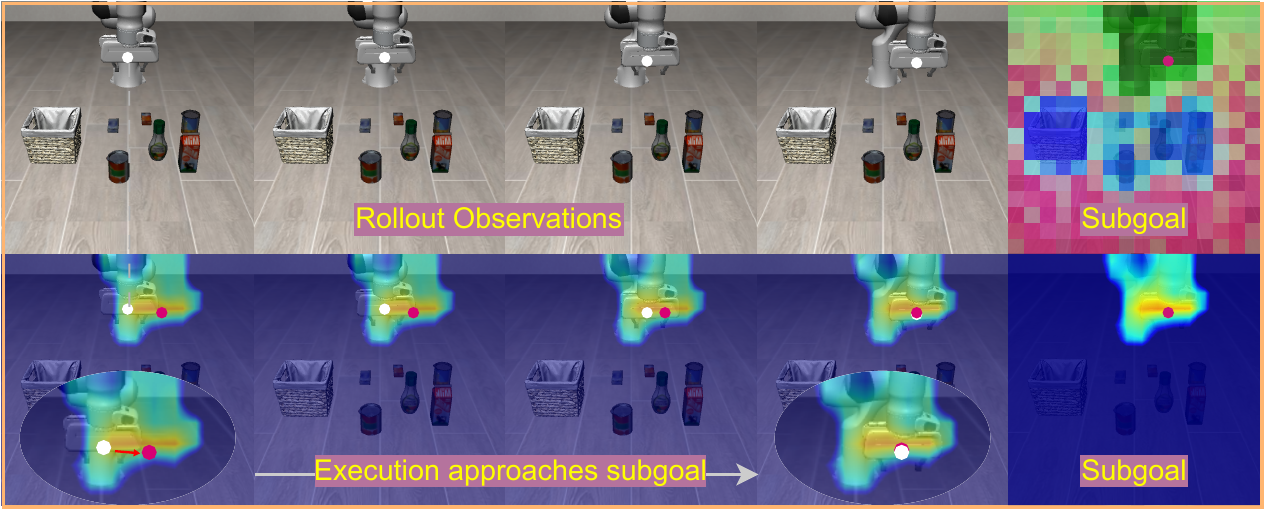
Subgoal-guided chunk execution on LIBERO.
LaWAM performs chunk-level latent subgoal conditioning: it predicts one latent visual subgoal for each action chunk, and the generated actions continually pursue that subgoal throughout execution.
Physical robots
Representative real-world rollouts.
Pick-and-place and drawer opening run on a Franka arm, while towel folding runs on a Quanta X1 bimanual robot, covering rigid-object, articulated-object, and deformable-object manipulation.

Dynamics Analysis
Shared latent transitions ground in unseen scenes and embodiments.
Following the paper's open-loop analysis, LaWM applies the same latent-action trajectory to different initial observations, including unseen scenes and new embodiments. The resulting context-specific latent rollouts suggest that latent actions encode abstract visual transitions, while LaWM grounds them in the current scene and embodiment.

Citation
Paper and citation.
@misc{chen2026lawam,
title = {LaWAM: Latent World Action Models for Efficient Dynamics-Aware Robot Policies},
author = {Chen, Jialei and Wang, Kai and Chen, Kang and Chen, Shuaihang and Gao, Feng and Tang, Wenhao and Li, Zhiyuan and Liu, Weilin and Yao, Zhuyu and Li, Boxun and Xu, Yuanbo and Yu, Chao},
journal = {arXiv preprint arXiv:2606.15768},
year = {2026},
archiveprefix = {arXiv},
primaryclass = {cs.RO}
}